Reinforcement Learning in Games
Deepmind este o companie marca Google care a folosit Reinforcement Learning in sistemul AlphaGo care l-a invins pe campionul mondial la Go in 2016, Go este un joc de strategie japonez, aceasta poate fi considerata una dintre cele mai mari realizari in inteligenta artificiala diferita de sistemul de la IBM care folosea arbori de decizie ca sa il invinga pe campionul mondial la sah. Strategia de la sah neputand fi aplicata in cazul jocului Go fiind mult mai complex si presupunand foarte multe cacule. Open AI este o companie fondata de Elon Musk care printre rezultate a fost participarea la un campionat de Dota in 2017 si invingerea unui campion, Dota fiind un joc de strategie complex pe calculator, o alta realizare in inteligenta artificiala de data asta de catre Facebook in 2019 este participarea la un turneu de poker si castigarea acestuia. Open AI pune la indemana oricui medii pentru experimentarea algoritmilor de Reinforcement Learning https://gym.openai.com/envs/#classic_control. Un exemplu de mediu este un joc ATARI:
O clasificare AI ar fi:
- Artificial General Intelligence (AGI, companii ca si DeepMind, OpenAI fac Research & Development), unde AI ar trebui sa fie capabil de mai multe sarcini, Reinforcement Learning combinat cu Deep Learning pare sa se incadreze la Artificial General Intelligence.
- Artificial Narrow Intelligence (ANI), AI care sunt capabile de un singur task, exemplu: computer vision, speech recognition, etc, machine learning este inclus in AI, AI reprezentand o clasa mai mare.
Reinforcement Learning este o ramura in machine learning care se ocupa cu agenti care iau decizi, actiuni intr-un mediu ca sa isi maximizeze recompensa cumulata.
Reinforcement Learning poate fi combinat cu Deep Learning si se obtine Deep Reinforcement Learning, un exemplu este DQN(Deep Q Network) obtinut prin combinarea unui algoritm de Reinforcement Learning (Q Learning) cu Deep Learning (Convolutional Neural Nets), acest algoritm poate fi aplicat unui joc de exemplu, invata din input-uri care sunt capturi de ecran din joc care sunt procesate cu Deep Learning (Convolutional Neural Nets). Deep Mind folosind aceasta tehnica, DQN (Deep Q Network) a reusit sa proiecteze un AI care sa invete sa joace toate 57 de jocuri din colectia ATARI, DeepMind’s AI can now play all 57 Atari games—but it’s still not versatile enough.
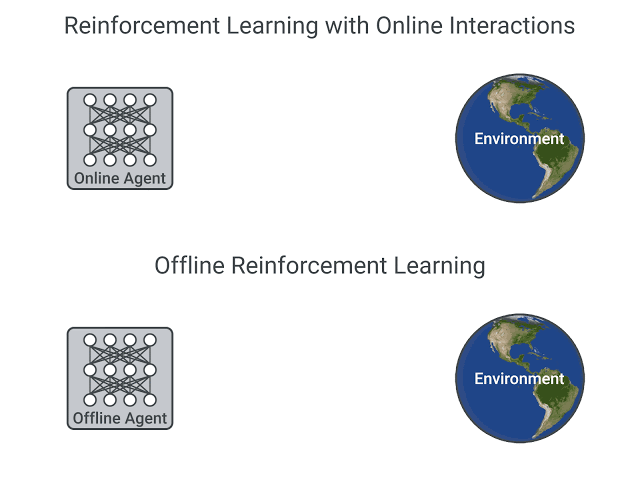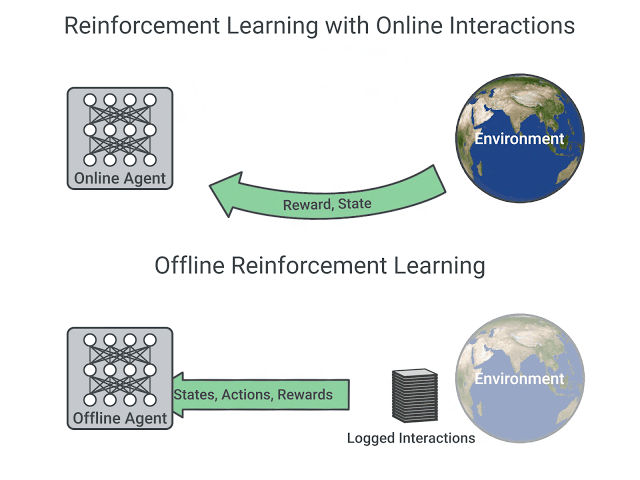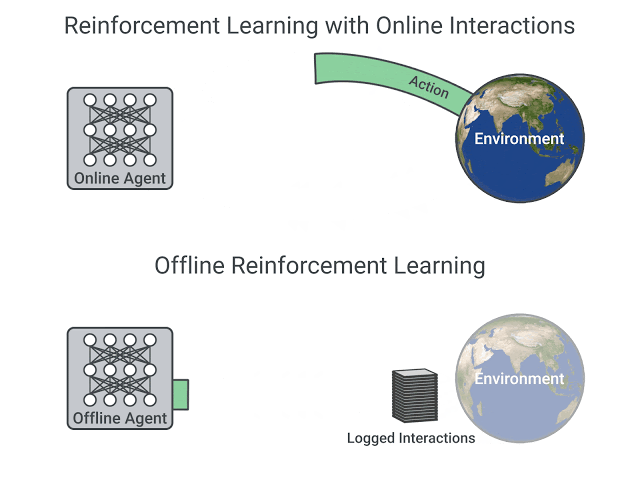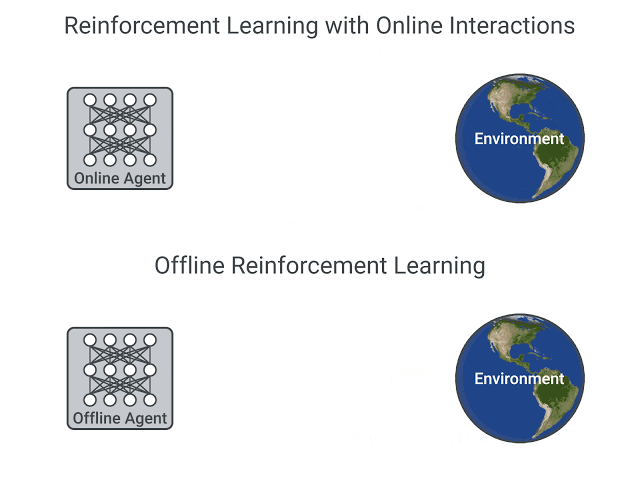
Q-Learning este o tehnică de reinforcement learning care asociază o utilitate pentru fiecare pereche stare-acțiune. Elementele de bază sunt : agent, stare, acțiune, recompensă. La orice moment, agentul se află într-o anumită stare și decide asupra uneia dintre mai multe acțiuni. Pentru acțiunea sa, agentul primește o recompensă. Scopul agentului este de a obține o recompensă totală maximă. Agentul lucrează cu o funcție de calitate (quality), pe care și-o adaptează pe măsură ce explorează mediul.

Curs Reinforcement LearningMediu este modelat ca si Markov Decision Process , multi algoritmi de reinforcement learning folosesc tehnici de programare dinamica.
Lanturi Markov, denumite dupa Andrey Markov, sunt sisteme matematice care sar dintr-o stare(o situatie de multimi de valori) in alta stare. De exemplu, daca faci un model de lant Markov a comportamentului unui copil, poti include "joaca", "mancare", "somn", si "plans" ca stari, care impreuna cu alte stari vor forma spatiul starilor: o lista cu toate starile posibile. Lantul Markov spune ca probabilitatea de a sari sau tranzitiona dintr-o stare in alta, adica sansa cau un copil care in prezent se joaca sa pice in somn in urmatoarele 5 minute fara sa planga mai intai.

Cu doua stari (A si B) in spatiu nostru de stari, vor fi 4 tranziti posibile(si nu 2 deoarece o stare pot tranzitiona inapoi in ea insusi. Daca suntem in starea 'A' se poate trazitiona in 'B' sau ramana in 'A'. Daca suntem in 'B' se poate tranzitiona in 'A' ori sta in 'B'. In diagrama acestor 2 stari, probabilitatea de a tranzitiona din orice stare in orice stare este de 0.5.
Desigur in realitate nu intotdeauna se deseneaza lanturi markov pe diagrame. In loc folosim o matrice de tranzitie in care sa definim probabilitatile de tranzitie. Fiecare stare in spatiu starilor este inclusa odata ca linie si coloana si fiecare celula in matricea de probabilitati.
Scenariu clasic in Reinforcement Learning, un agent ia actiuni intr-un mediu, care este interpretat ca recompensa de catre agent.

Ma gandesc ca si fiintele umane functioneaza dupa ceva similar cu Reinforcement Learning, evaluaza actiunile dupa recompensa si pedeapsa, dar este doar un punct de vedere.


Comentarii
Trimiteți un comentariu